Title here
Summary here
March 2, 201910 minutes
A look into the Stanford core NLP library and its capabilities.
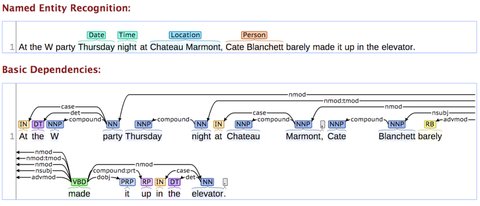
In this post, I will look into the Stanford core NLP library and its capabilities. Preprocessing text is an important first step in natural language processing. For example you might have some text that you want word tokenize and find out POS Tags for each and every word. Stanford core NLP comes to the rescue in that case.
Since the core API is written in java, as I assume most of practical machine learning/ deep learning tasks are done in python there’s a slight inconvenience to incorporate Stanford Core NLP to your machine learning pipeline directly. So, in this post, I will look into following three aspects of using Stanford core NLP:
Ok. Let us take a sample paragraph text. George Carlin Once famously said:
You got people like this around you? Country’s full of ’em now. People walkin’ around all day long every minute of the day, worried about everything. Worried about the air, worried about the water, worried about the soil. Worried about insecticides, pesticides, food additives, carcinogens, worried about radon gas, worried about asbestos, worried about saving endangered species.
Lemme tell ya bout endangered species, awright? Saving endangered species is just one more arrogant attempt by humans to control Nature. It’s arrogant meddling. It’s what got us in trouble in the first place. Doesn’t anybody understand that? Interfering with Nature. Over 90 percent, over, way over 90 percent, of the species that have ever lived on this planet, ever lived, are gone. Wooosh! They’re extinct. We didn’t kill them all. They just disappeared. That’s what nature does. They disappear these days at the rate of 25 a day—and I mean regardless of our behavior. Irrespective of how we act on this planet, 25 species that were here today will be gone tomorrow. Let them go gracefully. Leave Nature alone. Haven’t we done enough? We’re so self-important, so self-important. Everybody’s gonna save something now. Save the trees, save the bees, save the whales, save those snails. And the greatest arrogance of all, save the planet. What? Are these fucking people kidding me? Save the planet? We don’t even know how to take care of ourselves yet. We haven’t learned to care for one another—we’re gonna save the fuckin’ planet? I’m gettin’ tired of that shit. Tired of that shit. Tired.
I’m tired of fuckin’ Earth Day, I’m tired of these self-righteous environmentalists, these white bourgeoise liberals who think the only thing wrong with this country is there aren’t enough bicycle paths. People trying to make the world safe for their Volvos. Besides, environmentalist don’t give a shit about the planet, they don’t care about the planet, not in the abstract they don’t, not in the abstract they don’t. You know what they’re interested in? A clean place to live. Their own habitat. They’re worried that someday in the future they might be personally inconvenienced. Narrow, unenlightened self-interest doesn’t impress me. Besides, there is nothing wrong with the planet, nothing wrong with the planet. The planet is fine. The people are fucked. Difference. Difference. The planet is fine. Compared to the people, the planet is doin’ great! It’s been here four and a half billion years. Did you ever think about the arithmetic? The planet has been here four and a half billion years. We’ve been here, what? A hundred thousand? Maybe two hundred thousand and we’ve only been engaged in heavy industry for a little over two hundred years. Two hundred years versus four and a half billion. And we have the conceit to think that somehow we’re a threat? That somehow we’re gonna put in jeopardy this beautiful little blue-green ball that’s just a floatin’ around the sun? The planet has been through a lot worse than us. Been through all kinds of things worse than us. Been through earthquakes, volcanoes, plate tectonics, continental drift, solar flares, sunspots, magnetic storms, the magnetic reversal of the poles, hundreds of thousands of years of bombardment by comets and asteroids, and meteors, world-wide floods, tidal waves, world-wide fires, erosion, cosmic rays, recurring ice ages, and we think some plastic bags and some aluminum cans are going to make a difference?
The planet isn’t going anywhere. We are! We’re goin’ away. Pack your shit, Folks, we’re goin’ away. We won’t leave much of a trace either, thank god for that. Maybe a little styrofoam, maybe, little styrofoam. Planet’ll be here and we’ll be long gone. Just another failed mutation. Just another closed-end biological mistake, an evolutionary cul de sac. The planet will shake us off like a bad case of fleas, a surface nuisance. You wanna know how the planet’s doin’? Ask those people at Pompeii, who were frozen into position from volcanic ash. How the planet’s doin’. Wanna know if the planet’s alright, ask those people in Mexico City or Armenia, or a hundred other places buried under thousands of tons of earthquake rubble if they feel like a threat to the planet this week. How about those people in Kilauea, Hawaii who built their homes right next to an active volcano and then wonder why they have lava in the living room. The planet will be here for a long, long, long time after we’re gone and it will heal itself, it will cleanse itself ’cuz that’s what it does. It’s a self-correcting system. The air and the water will recover, the earth will be renewed, and if it’s true that plastic is not degradable well, the planet will simply incorporate plastic into a new paradigm: the earth plus plastic. The earth doesn’t share our prejudice towards plastic. Plastic came out of the earth. The earth probably sees plastic as just another one of its children. Could be the only reason the earth allows us to be spawned from it in the first place: it wanted plastic for itself. Didn’t know how to make it, needed us. Could be the answer to our age-old philosophical question, “Why are we here?” “Plastic, assholes.”
So, so, the plastic is here, our job is done, we can be phased out now. And I think that’s really started already, don’t you? I mean, to be fair, the planet probably sees us as a mild threat, something to be dealt with, but I’m sure the planet will defend itself in the manner of a large organism like a bee hive or an ant colony can muster a defense. I’m sure the planet will think of something. What would you do, if you were the planet trying to defend against this pesky, troublesome species? Let’s see, what might, viruses, viruses might be good, they seem vulnerable to viruses. And, viruses are tricky, always mutating and forming new strains whenever a vaccine is developed. Perhaps this first virus could be one that compromises the immune system in these creatures. Perhaps a human immuno deficiency virus making them vulnerable to all sorts of other diseases and infections that might come along, and maybe it could be spread sexually, making them a little reluctant to engage in the act of reproduction.
Well, that’s a poetic note. And it’s a start. But I can dream, can’t I? I don’t worry about the little things, bees, trees, whales, snails. I think we’re part of a greater wisdom than we’ll ever understand, a higher order, call it what you want. You know what I call it? The Big Electron. The Big Electron. Woooohhhh, woooohhhh, woooohhhh. It doesn’t punish, it doesn’t reward, it doesn’t judge at all. It just is, and so are we, for a little while. Thanks for being here with me for a little while tonight.Now, let us use the JAVA API to process the above file and see what we can do with the text above. The accompanying code is in a repository here. Let’s read the file like this:
String lines = null;
try {
Path filePath = FileSystems.getDefault().getPath(
".", "src", "main", "resources", "planet_is_fine.txt");
InputStream inputStream = Files.newInputStream(filePath);
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream));
lines = reader.lines().collect(Collectors.joining("\n"));
} catch (Exception e) {
e.printStackTrace();
}
return lines;Transgression : Maven Dependencies. The following are the maven dependencies to run stanford core nlp with English corpus:
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.2</version>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.2</version>
<classifier>models</classifier>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.2</version>
<classifier>models-english</classifier>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
</dependency>Now, for running basic NLP tasks, we have to create a pipeline with what annotators we want. A complete listing of annotators is available here. How stanford NLP works is that we have to create annotate the document. The example code creates a sample pipeline.
String carlinDialogues = CarlinFileReader.readCarlinFile();
Properties props = new Properties();
// Build the pipeline properties with what annotators you want
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props); // Build the pipeline
CoreDocument document = new CoreDocument(carlinDialogues);Here we use the following annotators: tokenize, ssplit, lemma, pos and ner for our pipeline and form the document using carlin dialogues.
Now let us tokenize and see what comes out as result:
pipeline.annotate(document);
List<CoreLabel> tokens = document.tokens();
System.out.println("We get the following tokens");
for (CoreLabel token : tokens) {
System.out.print(token + " ");
}
System.out.println();Now tokes
You-1 got-2 people-3 like-4 this-5 around-6 you-7 ?-8 ....
Let’s look at POS tags for the tokens.
List<String> posTags = new ArrayList<>();
document.sentences().forEach(
sentence -> posTags.addAll(sentence.posTags())
);
System.out.println(posTags);Ok. So far so good. Let us try and run coreNLP is server mode: The following code creates a server and runs it in port 5001 with a timeout of 15000 milli-seconds.
props.setProperty("server_id", "firstNlpServer");
StanfordCoreNLPServer server = new StanfordCoreNLPServer(props, 5001, 15000, false);
server.run();Now let us use the standard HTTP verbs to get the same functionality. We will use curl:
curl --data 'The quick brown fox jumped over the lazy dog.'
'http://localhost:5001/?properties={% raw %}{%22annotators%22%3A%22tokenize%2Cssplit%2Cpos%22%2C%22outputFormat%22%3A%22json%22 }{% endraw %}' -o - > curl_op.jsonThis is a perfect segue into using stanford core nlp in python. Now, we can see that we started the coreNLP server as shown above and send http requests to this server. Infact, the make things pythonic rather than jsonic. We will use a wrapper written in python providing us with the capabilities. The repository is here. This package contains a python interface for Stanford CoreNLP that contains reference implementation to interface with the StanfordCoreNLP Server. Now, to use this package we must first download the CoreNLP Server Jar files and set our corenlp home to a directory where the jar files are. In fact, I found a handy script that let’s you do that in linux.
#!/bin/bash
# A script written to download core nlp, written by originally by facebook research
read -p "Specify download path or enter to use default (../data/corenlp): " path
DOWNLOAD_PATH="${path:-../data/corenlp}"
echo "Will download to: $DOWNLOAD_PATH"
# Download zip, unzip
pushd "/tmp"
wget -O "stanford-corenlp-full-2018-10-05.zip" "http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip"
unzip "stanford-corenlp-full-2018-10-05.zip"
rm "stanford-corenlp-full-2018-10-05.zip"
popd
# Put jars in DOWNLOAD_PATH
mkdir -p "$DOWNLOAD_PATH"
mv "/tmp/stanford-corenlp-full-2018-10-05/"*".jar" "$DOWNLOAD_PATH/"
# Append to bashrc, instructions
while read -p "Add to ~/.bashrc CLASSPATH (recommended)? [yes/no]: " choice; do
case "$choice" in
yes )
echo "export CLASSPATH=\$CLASSPATH:$DOWNLOAD_PATH/*" >> ~/.bashrc;
break ;;
no )
break ;;
* ) echo "Please answer yes or no." ;;
esac
done
printf "\n*** NOW RUN: ***\n\nexport CLASSPATH=\$CLASSPATH:$DOWNLOAD_PATH/*\n\n****************\n" Now this will install corenlp and we have to export classpath to run the StanfordCoreNLP as well.
After this let us install python-stanford-corenlp using pip
pip install stanford-corenlpThe following example code can be used with python:
import corenlp
import os
os.environ['CORENLP_HOME'] = './data/corenlp'
text = "Chris wrote a simple sentence that he parsed with Stanford CoreNLP."
with corenlp.CoreNLPClient(annotators="tokenize ssplit pos lemma ner depparse".split()) as client:
ann = client.annotate(text)
# You can access annotations using ann
sentence = ann.sentence[0]
# The corenlp.to_text function is a helper function that
# reconstructs a sentence from tokens.
assert corenlp.to_text(sentence) == text
# You can access any property withing a sentence
print(sentence.text)
# Likewise for tokens
token = sentence.token[1]
print(token.lemma)
# Use the tokens regex patterns to find who wrote a sentence
pattern = '([ner: PERSON]+) /wrote/ /an?/ []{0,3} /sentence|artcile/'
matches = client.tokensregex(text, pattern)
# sentences contains a list with matches for each sentence.
assert len(matches["sentences"]) == 1
print(matches)